What is Data Science: An Historical Perspective#
Given how often the term “data science” gets thrown around, you would be excused for thinking that the meaning of the term was clearly understood. The reality, however, is that if you were to ask ten people working in the field you will almost certainly get ten different descriptions of what it is and what they do.
Part of that is deliberate obfuscation—data science is so trendy that everyone wants to claim that what they’re doing is data science in order to woo venture capitalists or to win research grants. Indeed, it has been said (half-joking, half-seriously): “Data science is Artificial Intelligence when you’re raising money, Machine Learning when you’re hiring, and it’s Logistic Regression when you actually have to get the job done.
But the ambiguity that surrounds the term “data science” is also the result of the fact that data science is not a mature discipline in the way that computer science, economics, or mechanical engineering are mature disciplines. And, as a young data scientist, that immaturity is important for you to understand, as it is both the source of some of the most exciting opportunities and also some of the biggest challenges you will face.
The Organization of Academia, Data Science, and You#
To explain what the term data science means in practice, we have to start by discussing a bit of the inside-baseball[1] of how academia operates. This may feel esoteric, but it’s important to understand because the way academia is organized has shaped the professional training — and thus the language and thought patterns — of most people you will encounter in the data science space. Understanding academia better, as a result, will not only help you understand the material you are exposed to in data science classes better, but also help you relate to your future peers and colleagues.
The idea that academia is deeply fragmented often surprises students, and understandably so. Universities love to pay lip service to the importance of interdisciplinarity and are quick to highlight successful interdisciplinary collaborations. But successful interdisciplinary collaborations are so notable precisely because they are the exception, not the rule. The reality is that academic research is starkly divided into disciplinary silos (e.g., computer science, statistics, political science, economics, and engineering). This isn’t because researchers aren’t interested in interdisciplinary collaborations, but rather that their professional imperatives push them to focus their attention on the priorities and language of their own departments and disciplines.[2]
Thus, while the past several decades have seen an unprecedented emergence of new methods across all of academia, the lack of intellectual cross-pollination across academic silos has resulted in disciplines failing to take full advantage of discoveries from other disciplines. Over time, each discipline has developed a perspective on computational methods that emphasizes its own intellectual priorities.
To illustrate, suppose we were interested in using patient data to reduce heart attacks. A computer scientist looking at this problem might use their discipline’s methods to predict which patients are most likely to experience a heart attack in the future using current patient data; a social scientist might focus on trying to understand the effect of giving patients a new drug on heart attack risk; and a statistician might focus on understanding how confident we should be in the conclusions reached by the computer scientist and social scientist.
This fragmentation has also resulted in a fragmentation of language around data science methodologies. Disciplines often come up with different terminology for the same phenomena, adding another layer of difficulty to efforts to work across departmental silos.
The result is a situation analogous to the Buddhist parable of the blind men and the elephant, wherein a group of blind people come upon an elephant, and upon laying hands on different parts of the elephant, they come to different conclusions about what lies before them. The person touching the tail declares “we have found a rope!”, while the person touching the leg declares “we have found a tree!”
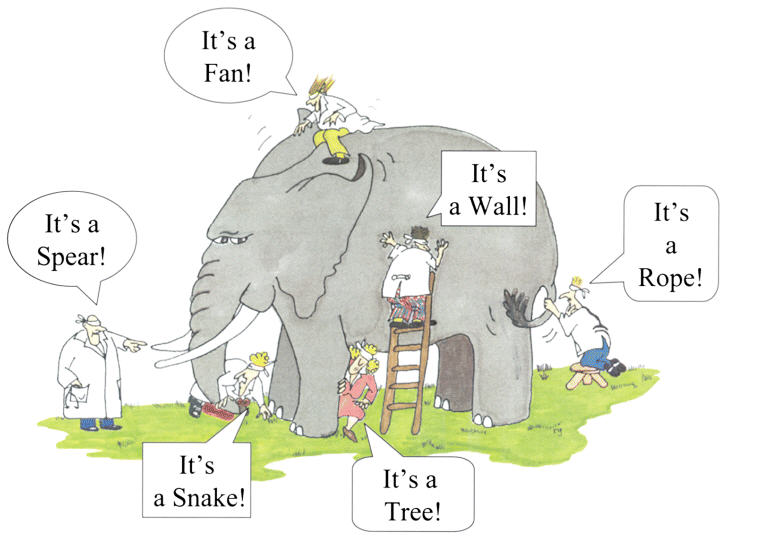
(Note: Not sure of original source of this image. Found it here, but need to figure out rights prior to anything about this becoming commercial! Lots of pics in public domain if needed, but not blindfolded scientists.)
And yet, as the poet John Godfrey Saxe wrote in his poem The Blind Men and the Elephant about this parable many centuries later:
And so these men of Indostan, Disputed loud and long, Each in his own opinion Exceeding stiff and strong, Though each was partly in the right, And all were in the wrong!
In recent years, however, there has been a growing appreciation of what can be gained from pulling together the insights that have been developed in different fields, despite the challenges of language and professional imperatives to such collaborations. And, at least amongst those who are serious about the development of data science as a discipline and not just a buzzword to use when raising money, is the promise of data science: to unify the different perspectives and methods for analyzing data. Or, to put it more succinctly: to finally see the whole elephant.
While the field is making progress towards “seeing the elephant as a whole,” however, as a result of this fragmented origin story, most people you will encounter in the world doing data science were trained in one of these academic silos. That means that depending on who you are working with and how they were trained, you may find your future colleagues using terms you’ve never heard before. And when that happens, it’s important to remember that while that may be because they’re talking about a concept you’ve yet to encounter, it may also simply be because they’re using different language for something you know. Similarly, you may also find senior colleagues unfamiliar with concepts that seem basic to you simply because you were exposed to perspectives that were alien to your colleague’s academic silo at the time they were trained. Indeed, given that data science education is finally becoming more unified, you should probably expect to learn a lot of ideas that even your more senior colleagues (or rather, especially your more senior colleagues!) were never exposed to.
And therein also lies some of the greatest opportunities. Precisely because of this intellectual fragmentation, there are lots of opportunities for taking insights from one intellectual silo and using them to solve problems in another — a kind of “intellectual arbitrage,” if you will.
The Data Analyst / Software Engineering Distinction#
In addition to this broader intellectual fragmentation, the world of data science also often feels oddly fragmented around the way people use the tools of data science.
One model of data science is what we will call the “data analyst” approach. Data scientists doing this type of work often collect data to answer specific questions—what is the effect of expanded government health insurance subsidies on mortality? what type of customer should we target with our new advertising campaign?. As a result, when they write code, they write it to be run against a specific set of data to answer a specific question.
The other model is what we will call the “software engineering” approach. Data scientists doing this type of work write software they plan to deploy to thousands or millions of users. This is the type of work that gets embedded in the apps on your phone, or that generates your movie recommendations at Netflix. As a result, when these data scientists write code, they are writing more sophisticated and generalizable programs.
To be clear, most data scientists do at least a bit of both types of work—data analysts may often write small programs or packages to aid in types of analysis they do a lot, and software engineers have to prototype and test new programs before they write a version that can be deployed broadly. But most people will eventually choose to specialize in one direction or another, and when you see data science resources in the world—especially ones about programming for data science—bear in mind that depending on your proclivities towards on approach or another, not all resources will be well suited to your interests.
I also want to draw attention to this distinction because it’s remarkable how dismissive most data scientists will be of the “other” type of data science, and I want to encourage you to both (a)not be so tribal yourself (both flavors of data science have their place, and help solve real world problems!), and (b) not be too surprised when you encounter people with irrationally strong opinions about which approach is the “right” approach to doing data science.